My thoughts on the Rarst/Jo Hoyle Progressive Enhancement/accessibility thing.
Happy 12th Birthday WordPress
27/05/2015 by

I almost didn’t write this post but it is time to celebrate WordPress’ 12th Birthday (12 years since the first release). But then I thought I wanted to say a couple of things. So, WordPress has come a long way. A huge collective of talented people maintain and improved every release. The business of WordPress is […]
WordPress news roundup #2
14/04/2015 by

The second episode of my WordPress news roundup. This month I decided to publish a podcast only version.
WordPress news roundup #1
18/03/2015 by
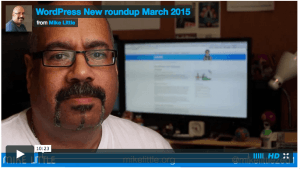
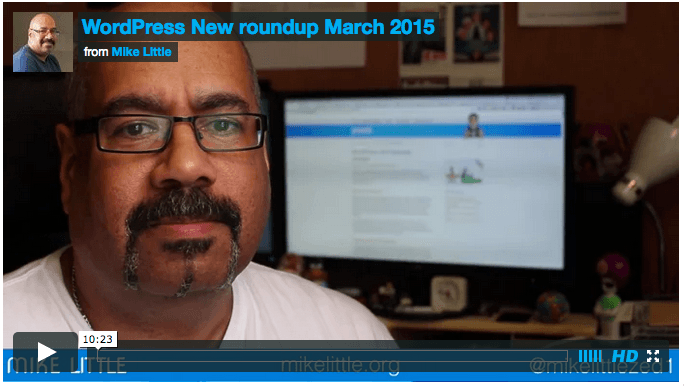
At the monthly WordPress user group I run here in Manchester, UK, I normally give a quick roundup of the latest WordPress news. This month I decided to share it with the wider world.
WordPress–12 years since the beginning
25/01/2015 by
As WordPress enters its 13th year, it’s interesting to reflect on what has been achieved in the last 12.
Happy 11th Birthday WordPress
27/05/2014 by
Happy 11th birthday WordPress! The software celebrates eleven years since the first release today!
WordPress–11 years since the beginning
26/01/2014 by
As WordPress enters its 12th year, it’s interesting to reflect on what has been achieved in the last 11.
WordCamp Lancaster, UK 2013
09/07/2013 by

This coming weekend is WordCamp Lancaster, and I am really looking forward to it.
How to Embed a Tweet in a WordPress Post or Page
05/07/2013 by
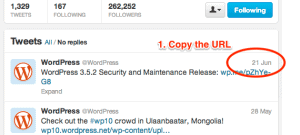
To embed a tweet in a WordPress post or page takes three simple steps.
Replacing a filter in a Twenty Twelve Child Theme
01/07/2013 by
Replacing filters set up in a parent theme like Twenty Twelve can be tricky.
 Loading
Loading








